November 15, 2019 - by CSCS
How good are we in multiplying matrices?
It is difficult to find a more abundant computation kernel than matrix multiplication. Studied for decades, with plethora of works both on theoretical analysis and efficient implementations, it may be surprising that this topic is not closed yet. However, researchers from Swiss National Computing Center and ETH Zurich found out that the existing BLAS libraries are often not efficient, especially in cases of non-square matrices, which naturally arise in a vast number of scientifically significant scenarios, e.g. in machine learning or quantum simulations. Furthermore, most of the existing implementations require careful fine-tuning of library-specific parameters in order to achieve decent performance, thus making it hard for scientists to take the best out of them, often resulting in a performance which is far from the optimal. The team presented a novel approach to speed-up the multiplication for matrices of any shape, which provably minimizes the necessary communication between the computing nodes. Their algorithm, called COSMA, outperforms the existing libraries up to an order of magnitude in some cases due to minimized communication and highly optimized implementation.
From communication lower bound to maximum performance - Best Paper Nomination for Supercomputing 2019
In HPC science, it is not enough to ask a question: are we faster than before, but rather: how fast can we ever get. Deriving tight theoretical lower bounds is crucial of assessing how much space for improvement is left. In this study, the researches have developed a mathematical abstraction based on the well-established pebbling game which allows to prove I/O lower bounds for many computational kernels. They applied it to the distributed matrix multiplication and the COSMA algorithm, which emerged directly from the constructive proof achieves this lower bound for all combinations of matrix shapes and available resources. On the other hand, careful analysis of existing algorithms show that none of available libraries is I/O optimal in all scenarios.
However, a careful evaluation indicated that while minimizing I/O did provide significant performance speedups, on its own it is not enough to achieve the peak performance on considered modern supercomputers. A series of low level optimizations was employed: data layout transformation based on maximum perfect graph matching minimizes the preprocessing cost. Algorithmic analysis of data dependencies allows static allocation of communication buffers of optimal size. Processor grid optimization relieves the programmer of the burden of manually finding optimal values of decomposition parameters - a big issue for ScaLAPACK users. The GPU-friendly inner tiling and stream overlap allows to achieve close-to-peak performance even for relatively small matrices, outperforming cublasXt by up to 30%. Using MPI one-sided leverages hardware RDMA communication to reduce the inter-node latency.
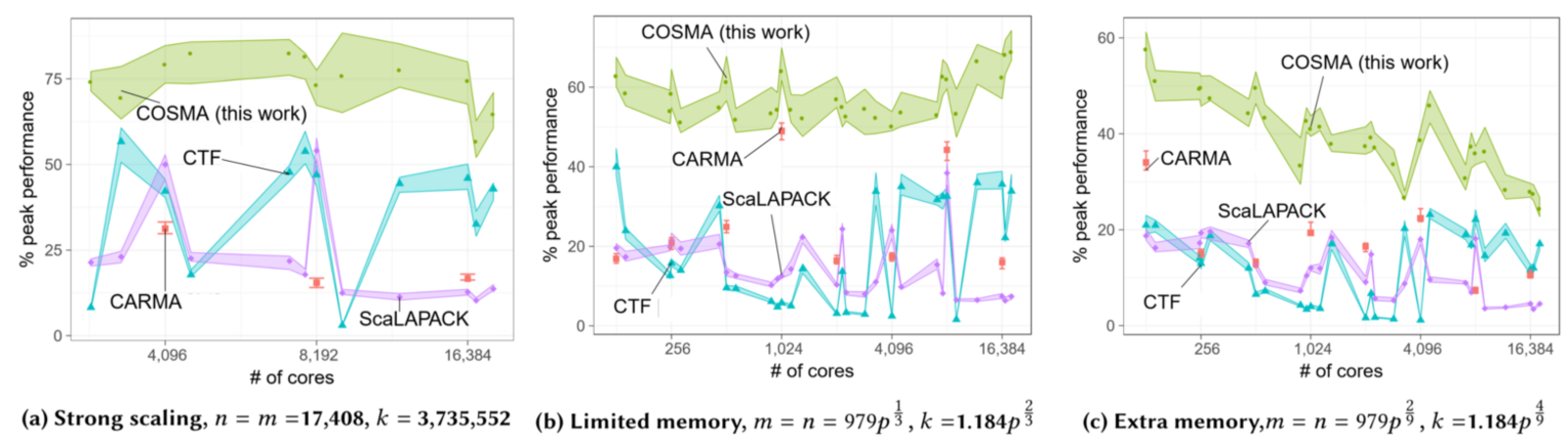
Experiments confirm theoretical predictions. COSMA was compared against Intel ScaLAPACK, CTF, and CARMA libraries. An experiment suite consisting of four classes of matrix shapes, processor counts varying from 128 to 18432, and three different scaling scenarios and matrix sizes from 2 thousands up to 3 billion rows shows that COSMA outperforms all competitors in all scenarios up to 13 times (2.1x on average). The total communication volume is reduced 1.9 times on average compared to the best asymptotically optimal libraries.
From science to applications
The team put a large effort in making COSMA library as easy to use as possible. The current version is available as an open source project on Github under the BDS-3 license and is Spack-installable. It supports arbitrary initial and final data layouts, handles all data types, offers transposition flags, and provides full support for ScaLAPACK API. Therefore, the end user can employ the communication optimal, highly-efficient COSMA library seamlessly to any ScaLAPACK-aided application without any change in the code, only linking to the COSMA library. The GPU back end supports both NVIDIA and AMD GPUs. COSMA also will soon be available in popular scientific simulation frameworks for molecular dynamics, like CP2K.
Reference:
Grzegorz Kwasniewski, Marko Kabić, Maciej Besta, Joost VandeVondele, Raffaele Solcà, Torsten Hoefler: "Red-Blue Pebbling Revisited: Near Optimal Parallel Matrix-Matrix Multiplication". Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC19), November 2019.