
January 18, 2022 - by Santina Russo
CSCS is gradually installing components of “Alps”, the Centre’s new supercomputer that will replace the current flagship machine “Piz Daint” by spring 2023. Thanks to the microarchitecture of its GPUs and its dedicated filesystem, “Alps” is expected to become one of the world’s most powerful AI-capable machines.
“The system will enable massively parallel computing using a vast amount of data,” says Torsten Hoefler, a professor at ETH Zurich and leader of the ETH Scalable Parallel Computing Lab. “Its architecture makes it particularly well suited for the calculations performed in machine learning.” In addition, the system supports features specifically designed for deep learning, such as sparsity support in hardware, which is a way to avoid storing and computing dispensable information and thus accelerate a neural network.
However, in order to achieve the most efficiency from such a powerful system, applications need to be smarter too. To this end, two computer scientists in Hoefler’s team, Roman Boehringer and Nikoli Dryden, have developed a software that speeds up the training of deep learning applications. Their new software called NoPFS (Near-optimal Pre-Fetching System) achieves this by clairvoyance: It expoits a pseudo-random and therefore predictable process in training more effectively than other tools have to date.
The cost of training
When working with neural networks and deep learning applications, their training is the single most costly process. In fact, a single training run of a high-level language model can cost around ten million dollars. During training, neural networks are exposed to data samples and desired labels for these samples. For an image recognition application, for instance, data samples will be pictures of an object — say, a cat. If the application wrongly classifies this as a dog, it subsequently rectifies itself based on the true value “cat” — its weights are updated, so that the application is likelier to identify the animal correctly next time. If this cycle is repeated with numerous samples from the dataset, the application eventually gets it right.
However, this learning process is tediously slow. It involves exposing the neural network to hundreds of thousands, sometimes millions of data samples, so a plethora of data loading and value updating steps are necessary. This loading and storing task that transfers information between filesystems and processors is called I/O in technical terms, and it is the most time-consuming and costly part of large-scale deep learning training: It gobbles as much as 85 percent of the entire training time, in fact. Experts call this the “I/O bottleneck”.
Looking into the crystal ball
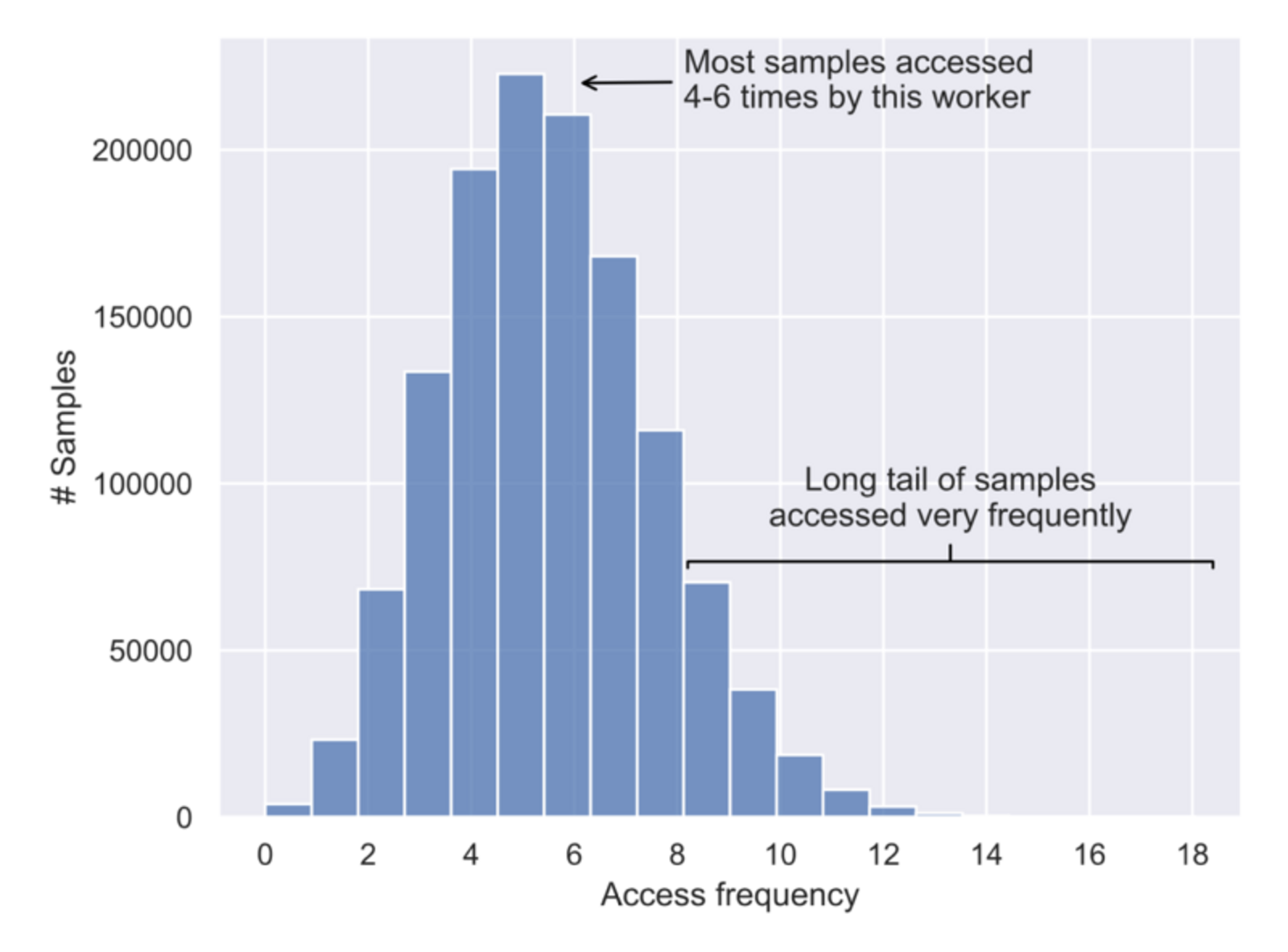
This is where the new software, NoPFS, comes into play. It uses the concept of clairvoyance to speed up this demanding data loading task. Indeed, data samples for training are, in principle, selected randomly, arranged into mini-batches consisting, for instance, of 32 data items, and then presented to the model until each data sample has been exposed to the model exactly once. Such a pass over the dataset constitutes one epoch of training. However, this process of sampling data items into mini-batches needs a known seed value to start, meaning that it is, in fact, only pseudo-random. Once the seed has been selected, the sequence of data samples is fixed and can be predicted.
“This is exactly what NoPFS does,” says Nikoli Dryden, a postdoctoral computer scientist in Hoefler’s group and the software’s main developer. NoPFS predicts the access pattern during an entire training run, meaning the sequence and frequency in which all training data items will be loaded to the executing processors to be exposed to the model, “which also means that the individual data items can be loaded in advance based on the frequency they will be accessed,” says Dryden. Most frequently accessed data items are cached directly in the Random-Access Memory (RAM), while a bit less demanded ones are cached on a local disk or a fast access compute node. “This way, the data items can be prefetched to the respective processors, which speeds up training,” explains Dryden.
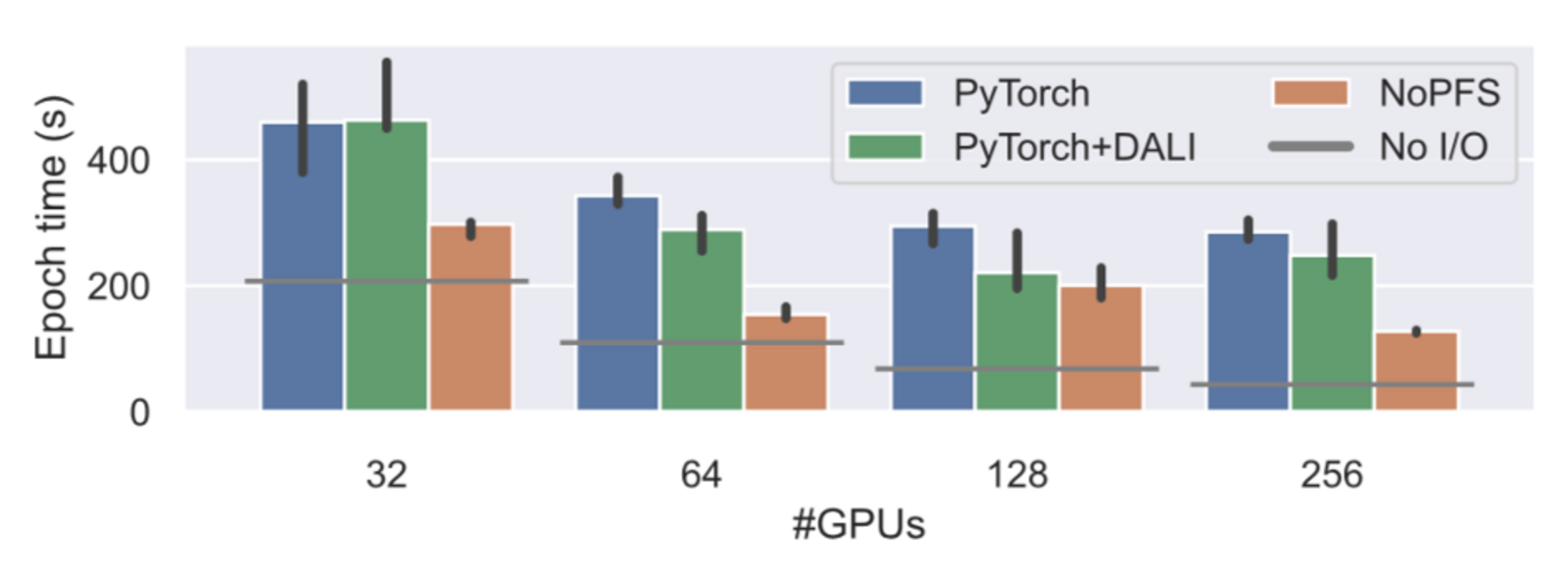
Training time cut in half
To evaluate the increased efficiency, the team applied NoFPS to training runs of different deep learning models on different HPC machines, including “Piz Daint” at CSCS. For their tests, the team used CosmoFlow, a deep learning application for predicting dark matter parameters of the universe, as well as the image recognition model ResNet-50 with two differently sized training datasets, ImageNet-1k and ImageNet-22k. The performance of NoFPS was compared to the data loading system of the widely used deep learning framework PyTorch and the NVIDIA Data Loading Library (DALI).
The results show that, depending on the HPC system, the number of employed GPUs and the size of the training dataset, NoFPS accelerated training considerably. Training was notably accelerated by a factor of up to 2.1 for CosmoFlow, up to 2.4 for ImageNet-22k, and up to a stunning 5.4 for ImageNet-1k.
“In general, we achive larger performance improvements the more GPUs we use,” says Hoefler. However, he cautions that these results were achieved with filesystems that are not optimal for deep learning calculations. With dedicated systems, such as “Alps”, the efficiency increase may be somewhat lower. “Still, NoFPS will provide a significant speed-up, even on systems dedicated to deep learning,” says Hoefler.
Most relevant for scientific applications
The concept NoPFS employs is not brand new. In fact, many existing deep learning frameworks use a simplified version of the same idea: They look one or more steps ahead and start fetching the next data items in advance, thereby gaining some performance improvement. However, no tool before has used clairvoyance to its limits and as consequently as NoPFS does all the way through a training run.
“The shorter training time NoPFS achieves will be especially relevant for scientific research applications, and therefore for CSCS and its users,” says Hoefler. In a scientific context, machine learning is typically used in one of two ways: Firstly, neural networks can be used to analyse and refine the results of simulations; secondly, they can accelerate simulations by replacing components of the simulation code. Hoefler, Dryden and their co-workers have recently published a paper describing how the team replaced the component for statistical post-processing in the weather forecast model of the European Centre for Medium-Range Weather Forecasts ECMWF with a post-processing step performed by a neural network. Applied to global data, the new hybrid model achieved an improved forecast skill of over 14 percent.
Nonetheless, getting there involves a lot of neural network training. “Mostly, such cases require training of various deep learning models to find the one that works best,” says Hoefler. “This requires weeks of computing time. These kind of applications will therefore benefit the most from NoPFS and the efficiency gain it provides.” In future developments, the team aims to further optimise the clairvoyance-based method of pre-caching data to offer even better performance.
Image above: Adobe Stock
References:
- Dryden N., Böhringer R., Ben-Nun T. and Hoefler T.: Clairvoyant Prefetching for Distributed Machine Learning I/O. SC’21: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (2021). DOI: https://doi.org/10.1145/3458817.3476181
- Grönquist P., Yao C., Ben-Nun T., Dryden N., Dueben P., Li S.and Hoefler T.: Deep learning for post-processing ensemble weather forecasts. Phil. Trans. R. Soc. (2021). DOI: https://doi.org/10.1098/rsta.2020.0092
This article may be used on other media and online portals provided the copyright conditions are observed.